
Instruction-driven history-aware policies for robotic manipulations
Pierre-Louis Guhur1, Shizhe Chen 1, Ricardo Garcia 1, Makarand Tapaswi 2, Ivan Laptev 1, Cordelia Schmid 1
1Inria, École normale supérieure, CNRS, PSL Research University
2IIIT Hyderabad

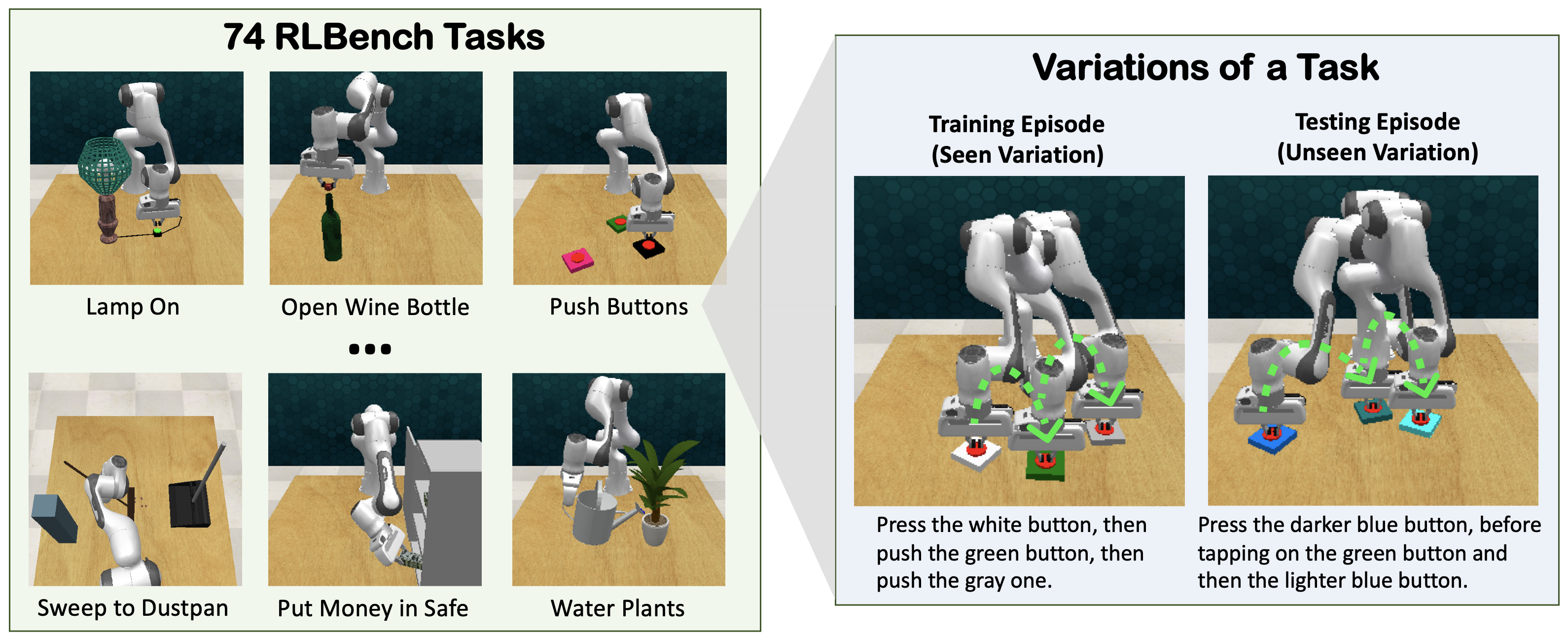
Hiveformer jointly models instructions, views from multiple cameras, and historical actions and observations with a multimodal transformer for robotic manipulation.

